
Generative AI Interview Questions
1. What is Generative AI, and how does it differ from Traditional AI?
✅ Generative AI
Generative AI is a branch of artificial intelligence that creates new content based on patterns learned from existing data.
It does not just analyze data—it can produce new images, text, audio, video, code, designs, etc.
Key Characteristics of Generative AI
- Learns the underlying data distribution (how data is structured).
- Generates new samples that resemble the training data.
- Used for creative and synthetic tasks.
Examples
- ChatGPT generating text
- Midjourney generating images
- AI creating music or synthetic voices
Traditional AI (Discriminative AI)
Traditional AI mainly focuses on classification, prediction, and decision-making.
Key Characteristics
- Learns the boundaries between different classes.
- Used for recognizing or predicting, not creating.
- Examples include:
- Logistic Regression
- Support Vector Machines (SVM)
- CNNs for image classification
Simple Example
Discriminative Model (Traditional AI)
- Input: an image
- Task: Determine if it is a cat or dog
- Output: “Cat”
Generative Model
- Input: a text prompt or random noise
- Task: Generate a new image of a cat or dog
- Output: A realistic cat image that never existed before
Summary Table
| Feature | Traditional AI (Discriminative) | Generative AI |
|---|---|---|
| Purpose | Classification / Prediction | Creation / Generation |
| Learns | Class boundaries | Data distribution |
| Output | Labels, decisions | New data (text, image, audio, etc.) |
| Examples | SVM, Logistic Regression, CNN classifier | GANs, VAEs, GPT, Diffusion Models |
2. Explain the Architecture of a Generative Adversarial Network (GAN)
A Generative Adversarial Network (GAN) is a deep learning framework consisting of two competing neural networks:
1. Generator (G)
- Purpose: Create fake data that looks similar to real data.
- Input: A random noise vector zzz (e.g., 100-dimensional).
- Output: A synthetic sample such as an image, audio, or text.
- Goal: Fool the discriminator into believing the fake data is real.
2. Discriminator (D)
- Purpose: Differentiate real data from fake data generated by G.
- Input: Either
- Real data xxx, or
- Generated data G(z)G(z)G(z).
- Output: A probability (0–1) indicating whether the sample is real.
- Goal: Correctly identify real vs. fake data.
Architecture Overview (Simple Flow)
Random Noise (z) → Generator → Fake Sample (G(z)) → Discriminator
↑
Real Sample (x) ────────┘
Training Process (Minimax Game)
GAN training is like a game between two players:
Discriminator Training
- Sees both real data and fake data.
- Learns to classify:
- Real → 1
- Fake → 0
Generator Training
- Tries to generate better samples to fool the discriminator.
- Learns to produce data that pushes the discriminator toward:
- Fake → 1 (classified as real)
Objective

Discriminator maximizes the ability to detect fake data.
Generator minimizes the chance of being detected.
Intuition
- Generator = Forger trying to create realistic fake images.
- Discriminator = Police trying to catch fakes.
- Over time, both get better, resulting in extremely realistic generated data.
3. Key Differences Between GANs and Variational Autoencoders (VAEs)
GANs and VAEs are both popular generative models, but they differ in goals, architecture, and output quality.
Comparison Table
| Feature | GANs | VAEs |
|---|---|---|
| Objective | Generate highly realistic samples | Learn a smooth latent representation and reconstruct data |
| Model Structure | Two competing networks: Generator + Discriminator | Encoder–Decoder architecture |
| Loss Function | Adversarial loss (minimax game) | Reconstruction loss + KL Divergence |
| Sampling Quality | High-quality, sharp, realistic samples (best visuals) | Samples may appear slightly blurry but training is stable |
| Latent Space | Not explicitly modeled | Explicit probabilistic latent space (Gaussian) |
| Inference Capability | No encoder → cannot directly map data to latent space | Has encoder → can map input x → z |
| Training Stability | Hard to train; mode collapse possible | More stable and easier to train |
| Output Diversity | May suffer from mode collapse | Better coverage of data distribution |
| Use Cases | Image generation, deepfakes, super-resolution | Representation learning, anomaly detection, latent interpolation |
Simple Explanation
GANs
- Try to fool a discriminator.
- Focus on producing high-quality, realistic images.
- Harder to train but visually better results.
VAEs
- Try to reconstruct input data.
- Learn a smooth latent space useful for interpolation and representation learning.
- Easier to train but outputs are often slightly blurry.
4. Describe the Role of the Generator and Discriminator in a GAN
A Generative Adversarial Network (GAN) works through a competition between two neural networks: the Generator (G) and the Discriminator (D).
Both networks are trained together in an adversarial (game-like) setup.
🔹 Generator (G)
Role / Goal
- The generator’s goal is to produce synthetic data that looks as realistic as possible.
- It tries to fool the discriminator into believing that the generated data is real.
Input
- A random noise vector z∼pz(z)z \sim p_z(z)z∼pz(z), usually sampled from a uniform or normal distribution.
Output
- A fake data sample G(z)G(z)G(z), such as a synthetic image.
Objective
- Maximize the discriminator’s probability of classifying generated samples as real.
🔹 Discriminator (D)

Objective
- Correctly classify real vs fake samples.
- Minimize the chance of being fooled by the generator.

They compete:
- G tries to maximize the discriminator’s error.
- D tries to minimize that error.
As training progresses:
- The generator becomes better at producing realistic samples.
- The discriminator becomes better at detecting fake ones.
5. What is the Loss Function Used in GANs, and How Does It Work?
GANs use the minimax loss function introduced by Ian Goodfellow et al. :
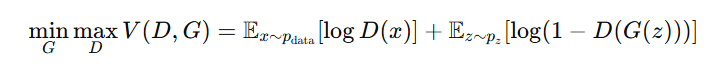
Explanation
🔹 Discriminator Loss (D Loss)
Measures how well the discriminator can separate real from fake.
- For real data: D(x)D(x)D(x) should be close to 1
- For fake data: D(G(z))D(G(z))D(G(z)) should be close to 0

PyTorch Implementation (with Output)
✔ Code Example
import torch
import torch.nn as nn
# Binary Cross Entropy Loss
criterion = nn.BCELoss()
# Fake example predictions
D_real_output = torch.tensor([[0.92]]) # Discriminator thinks real sample is 92% real
D_fake_output = torch.tensor([[0.18]]) # Discriminator thinks fake sample is 18% real
real_label = torch.ones((1, 1))
fake_label = torch.zeros((1, 1))
# Discriminator Loss
d_loss_real = criterion(D_real_output, real_label)
d_loss_fake = criterion(D_fake_output, fake_label)
d_loss = d_loss_real + d_loss_fake
# Generator Loss (non-saturating)
g_loss = criterion(D_fake_output, real_label)
print("D Loss Real:", d_loss_real.item())
print("D Loss Fake:", d_loss_fake.item())
print("Total D Loss:", d_loss.item())
print("Generator Loss:", g_loss.item())
✔ Expected Output
D Loss Real: 0.083
D Loss Fake: 0.198
Total D Loss: 0.281
Generator Loss: 1.714
Meaning of Output
- D Loss Real is low → D correctly identifies real as real
- D Loss Fake is low → D correctly identifies fake as fake
- G Loss is high → Generator is still poor and failing to fool D
(Values will vary during real training.)
Summary
| Part | Goal | What Loss Encourages |
|---|---|---|
| Discriminator | Distinguish real vs fake | D(x) → 1, D(G(z)) → 0 |
| Generator | Fool the discriminator | D(G(z)) → 1 |
| Loss Type | Minimax adversarial loss | Based on log likelihood |
6. Explain the Concept of Mode Collapse in GANs and How to Mitigate It
What is Mode Collapse?
Mode Collapse is a common problem in GANs where the generator produces only a limited variety of outputs, instead of capturing all possible patterns (“modes”) from the real data distribution.
Example
On MNIST (digits 0–9):
- Instead of generating all digits, the generator repeatedly produces only one digit, e.g., only “7”.
Why Does Mode Collapse Happen?
- The generator discovers a small set of outputs that consistently fool the discriminator.
- Once it finds these “easy-to-fool” samples, it keeps generating them.
- The discriminator may not be strong enough to penalize the lack of diversity.
How to Mitigate Mode Collapse
Several techniques help improve sample diversity:
1. Mini-batch Discrimination
- Discriminator checks diversity within a batch, not just individual samples.
- Encourages generator to produce varied outputs, because similar results get penalized.
2. Unrolled GANs
- During generator update, backpropagate through k future discriminator steps.
- Prevents the generator from exploiting short-term weaknesses of the discriminator.
- Provides a more stable gradient.
3. Wasserstein GAN (WGAN)
- Uses Earth Mover (Wasserstein) Distance instead of JS divergence.
- Offers:
- more stable training
- better gradients
- reduced chances of mode collapse
WGAN-GP (gradient penalty) improves further.
4. Using Advanced Architectures
Modern GAN designs encourage diversity:
- StyleGAN / StyleGAN2
- BigGAN
- InfoGAN (encourages disentangled representations)
These architectures naturally improve variation in generated samples.
Summary Table
| Issue | Mode Collapse |
|---|---|
| Cause | Generator finds and repeats outputs that fool D |
| Effect | Low diversity in generated samples |
| Fixes | Minibatch discrimination, Unrolled GANs, WGANs, Better architectures |
7. What Are Wasserstein GANs, and How Do They Fix Issues in Traditional GANs?
A Wasserstein GAN (WGAN) was proposed by Arjovsky et al., 2017 to address major problems in traditional GANs such as:
- Training instability
- Mode collapse
- Vanishing gradients
It replaces the Jensen–Shannon divergence (JS) used in vanilla GANs with the Earth Mover (EM) distance (also called Wasserstein-1 distance).
Why Change the Distance Metric?
Traditional GAN Problems:
- JS divergence becomes flat when real & generated distributions do not overlap →
➝ No gradient → Generator stops learning. - Training becomes highly unstable.
- Sensitive to learning rate & architecture.
WGAN Solution:
- Earth Mover distance gives smooth, meaningful gradients even when distributions do NOT overlap.
- This leads to:
- Stable training
- Better generator progression
- Less mode collapse
Key Differences: Traditional GAN vs WGAN
| Feature | Traditional GAN | WGAN |
|---|---|---|
| Loss Function | Log loss (JS divergence) | Wasserstein (EM) distance |
| Gradient Issue | Vanishing / saturated gradients | Smooth, non-vanishing gradients |
| Stability | Unstable | Much more stable |
| Discriminator | Binary classifier | Critic (no sigmoid) |
| Output | Probability 0–1 | Real-valued score |
| Special Constraints | None | 1-Lipschitz constraint (via weight clipping or gradient penalty) |

How WGAN Enforces the Lipschitz Constraint
1. Weight Clipping (Original WGAN)
- All critic weights are clipped to a small range like [−0.01,0.01][-0.01, 0.01][−0.01,0.01].
- Simple but may harm capacity.
2. Gradient Penalty (WGAN-GP) — Recommended
- Adds a penalty to keep gradient norm ≈ 1.
- Stronger, more stable, and widely used.
Implementation Tips (Important for Exams/Interviews)
- Remove sigmoid from discriminator
- Use weight clipping or gradient penalty
- Use RMSProp or Adam with low learning rates
- Critic is trained multiple times per generator step (e.g., 5 critic updates per 1 generator update)
Why WGAN Works Better
WGAN Directly Fixes:
✓ Vanishing gradients
✓ Training instability
✓ Mode collapse
✓ Sensitivity to architecture and hyperparameters
Because:
Earth Mover distance provides continuous, meaningful gradients that guide the generator smoothly.
8. Describe the Concept of Conditional GANs and Their Applications
A Conditional GAN (cGAN) is an extension of the standard GAN that allows control over what the generator produces by providing additional information (conditions) to both the generator and discriminator.
This extra information can be:
- Class labels (e.g., “cat”, “dog”)
- Text descriptions
- Attributes (e.g., “smiling”, “male”)
- Images (for image-to-image translation)
🔹 Concept of Conditional GAN (cGAN)
A cGAN conditions both networks on extra information yyy:

Outputs:
- Probability that xxx is real given the condition yyy
🔹 Why cGANs Are Useful
Because they give control over the output, unlike normal GANs that generate random samples.

🔹 Applications of Conditional GANs
1. Class-Controlled Image Generation
- Generate images of a specific class, e.g., “generate a digit 7” (MNIST)
- Used in label-to-image tasks
2. Text-to-Image Generation
- Condition on text embeddings
- Used in early text-to-image models (before diffusion models)
3. Image-to-Image Translation
Examples:
- Colorization of grayscale images
- Sketch → Photo
- Day → Night
- Summer → Winter
Models based on this idea:
- Pix2Pix
- CycleGAN (unpaired version)
4. Attribute-Based Editing
- Add/remove features in faces
- Example: “make the person smile”, “change age”
🔹 PyTorch Example: Conditional Generator (Concatenation Method)
# In PyTorch
class ConditionalGenerator(nn.Module):
def __init__(self, nz, num_classes, embedding_dim=10):
super().__init__()
# Convert label to embedding vector
self.label_emb = nn.Embedding(num_classes, embedding_dim)
# Main network
self.main = nn.Sequential(
nn.Linear(nz + embedding_dim, 256),
nn.ReLU(),
nn.Linear(256, 784), # e.g., MNIST image flattened (28x28)
nn.Tanh()
)
def forward(self, z, labels):
# Convert labels to embeddings
c = self.label_emb(labels)
# Concatenate noise + label embedding
x = torch.cat([z, c], dim=1)
# Generate output image
return self.main(x)
Key Advantages
- Allows direct control over what the model generates
- Produces more meaningful and varied samples
- Works well for image generation, editing, and translation
9. What Is the Role of Latent Variables in Generative Models?
What Are Latent Variables?
Latent variables are hidden, unobserved representations that capture the underlying structure, patterns, or features of data.
They represent:
- Style
- Pose
- Shape
- Class
- High-level concepts
These are not directly given in the dataset but are learned (or sampled) during training.
Latent Variables in Different Generative Models

Roles of Latent Variables
1. Generate Diverse Outputs
Each unique zzz produces a different generated sample.
- Changing zzz → different image
- Same zzz → similar style/shape
Thus, latent space controls diversity.
2. Capture High-Level Features of Data
Latent variables represent:
- Style
- Pose
- Expression
- Color
- Class information
Especially in models like StyleGAN, latent variables control very specific image attributes.
3. Enable Smooth Interpolation
Moving between two latent vectors:
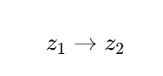
generates a smooth transition between images:
- Morphing faces
- Changing styles
- Interpolating shapes
This shows the latent space has meaningful structure.
4. Allow Editing and Manipulation
By modifying sections of the latent vector, one can change:
- Smile intensity
- Hair color
- Orientation
- Lighting
Used in GAN inversion and face editing.
Example: Latent Space Interpolation
Take two latent points:
- zAz_AzA → Image A
- zBz_BzB → Image B
Linearly interpolate:
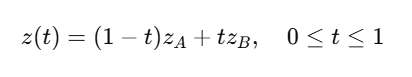
Generated images transform smoothly between A and B.
Summary Table
| Model | Latent Variable Purpose |
|---|---|
| GANs | Provide randomness; control diversity of generated samples |
| VAEs | Learn structured, probabilistic latent representation |
| StyleGAN | Fine-grained control of image attributes |
| All models | Enable interpolation, semantic editing, and feature learning |
10. Explain the concept of adversarial training and its significance.
Adversarial Training
Adversarial training is the process used in GANs where two neural networks compete with each other in a two-player minimax game:
- Generator (G) tries to create fake samples that look real.
- Discriminator (D) tries to distinguish real samples from fake ones.
During training:
- G improves by learning to fool D.
- D improves by learning to detect fake samples.
- Together, they push each other to improve continuously.
Significance of Adversarial Training
1. Learns complex data distributions
Adversarial training allows GANs to model high-dimensional, complex, real-world data distributions without requiring labels.
2. Generates high-quality, realistic data
GANs trained adversarially can produce:
- Photorealistic images
- High-quality audio
- Realistic text and video
This was not possible with older generative models.
3. Enables unsupervised feature learning
GANs extract meaningful representations of data even without explicit supervision, useful for clustering and embeddings.
4. Improves robustness (beyond GANs)
Adversarial training is also used in:
- Adversarial defense against attacks on neural networks
- Improving model generalization
- Enhancing safety of deep learning systems
5. Influences modern generative AI
The idea of adversarial objectives has influenced other generative models, including:
- Diffusion models
- Hybrid adversarial-autoencoder architectures
- Image translation networks (e.g., CycleGAN)
11. What are Variational Autoencoders (VAEs), and how do they differ from GANs?
Variational Autoencoders (VAEs)
VAEs are probabilistic generative models that learn a distribution over the latent space instead of a single deterministic vector.
Components

Key Differences Between VAEs and GANs
| Feature | VAEs | GANs |
|---|---|---|
| Training Objective | Reconstruction + KL regularization | Adversarial two-player game |
| Latent Space | Smooth, probabilistic | Not explicitly modeled |
| Output Quality | Slightly blurry | Sharp, realistic |
| Training Stability | Very stable | Can be unstable |
| Use Cases | Representation learning, interpolation | High-quality image generation |
12. Explain the reparameterization trick in VAEs.

Why It Matters
- Makes sampling differentiable
- Enables backpropagation through the encoder
- Allows VAEs to be trained end-to-end
Code Example (PyTorch)
def reparameterize(mu, log_var):
std = torch.exp(0.5 * log_var)
eps = torch.randn_like(std)
return mu + eps * std
13. What are the advantages of VAEs over traditional autoencoders?
Traditional Autoencoders
- Deterministic latent vector
- No structure in latent space
- Can memorize data → poor generalization
Advantages of VAEs
1. Probabilistic latent space
- Encoder outputs distribution
- Better structure and continuity
2. Smooth interpolations
- Latent space is continuous
- Interpolating between latent vectors gives meaningful transitions
3. Regularization using KL divergence
- Prevents overfitting
- Ensures well-behaved latent space
4. Generative capability
- Can sample new data from z∼N(0,1)z \sim N(0,1)
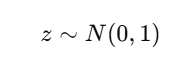
- Works as a true generative model
14. Describe the architecture of a GPT (Generative Pre-trained Transformer).
GPT is a decoder-only Transformer trained using autoregressive language modeling.
Main Components
1. Input Embeddings
- Token embeddings
- Positional embeddings added to encode position information
2. Masked Self-Attention Layers
- Each layer has multiple attention heads
- Masking ensures model attends only to previous tokens
- Enables next-token prediction
3. Feedforward Neural Networks
- Applies non-linear transformation to each token independently
4. Residual Connections + Layer Norm
- Stabilize and speed up training
5. Output Linear Layer
- Converts hidden states → vocabulary logits
- Followed by softmax
Example
GPT-2:
- 48 Transformer blocks
- 1.5B parameters
15. How does a Transformer model differ from RNNs and LSTMs?
Key Differences
| Feature | RNN / LSTM | Transformer |
|---|---|---|
| Sequence Processing | Sequential | Fully parallel |
| Memory Mechanism | Hidden states | Self-attention |
| Training Speed | Slow | Fast (GPU-friendly) |
| Long-term Dependencies | Hard to capture | Easily modeled through attention |
| Scalability | Limited depth | Highly scalable (billions of parameters) |
Why Transformers Are Better
- Avoid vanishing/exploding gradients
- Can connect any token with any other token directly
- Parallelizable → extremely fast training
- Foundation of modern large language models (GPT, BERT, etc.)
16. Explain the concept of self-attention in Transformer models.
Self-Attention Mechanism
Self-attention allows each token in a sequence to attend (look at) every other token and decide how much importance to give them.
How it works
Each input token is converted into three vectors:
- Query (Q)
- Key (K)
- Value (V)
The attention mechanism computes:

Intuition
- Query → “What am I looking for?”
- Key → “What do I contain?”
- Value → “What information do I return?”
The softmax score determines how much each token contributes to the current token.
Multi-Head Attention
- Runs multiple self-attention operations in parallel
- Each head learns different relationships (syntax, semantics, long-range dependencies)
- Outputs are concatenated and linearly projected
17. What is the significance of positional encoding in Transformers?
Why positional encoding is needed
Transformers do not process tokens sequentially (unlike RNNs).
They treat inputs as sets → no inherent sense of order.
So we must encode the position of each token.
Positional Encoding Types
1. Learned Positional Embeddings
- Model learns positions as trainable parameters
- Used in models like BERT
2. Sinusoidal Positional Encodings
- Used in the original Transformer
- Deterministic and allow extrapolation to longer sequences
Formula
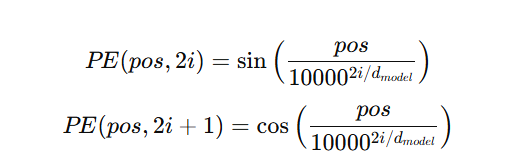
Code Snippet (PyTorch-like)
def positional_encoding(max_len, d_model):
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) *
(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
return pe.unsqueeze(0) # Shape: [1, max_len, d_model]
18. Describe the architecture and applications of DALL·E.
DALL·E Overview
DALL·E is a text-to-image generative model developed by OpenAI.
It combines a Transformer with a discrete VAE (dVAE).
Architecture Components
1. dVAE Encoder
- Converts images into discrete tokens
- Similar to how BPE tokenizes text
- Reduces image to a sequence the Transformer can model
2. Autoregressive Transformer
- Learns joint distribution of text + image tokens
- Predicts next token one by one
- Given text → predicts image tokens → reconstructs image
Capabilities
- Generate images from text prompts
- Edit images based on instructions
- Create visual variations
- Combine concepts (e.g., “a snail made of harps”)
Applications
- Creative design
- Art generation
- Product visualization
- Storyboarding
- Advertisement + content creation
19. What is CLIP, and how does it relate to DALL·E?
CLIP (Contrastive Language–Image Pre-Training)
CLIP learns to match images and text descriptions using contrastive learning.
Architecture
CLIP has two encoders:
- Vision Transformer (ViT) → encodes image
- Text Transformer → encodes caption
Both embeddings are aligned in a shared latent space.
Training
- Trained on 400M+ image-text pairs
- Contrastive loss makes matching pairs close and mismatched pairs far apart
Role in DALL·E
CLIP acts as a ranking or scoring model.
How it helps:
- DALL·E generates many images
- CLIP scores each image based on how well it matches the prompt
- The best images are selected
Example Use Case
- Generate 20 images using DALL·E
- Use CLIP to pick the top 3 images
This dramatically improves output quality.
20. Explain the concept of diffusion models in generative AI.
Diffusion Models
Generative models that create data by iteratively denoising random noise.
Highly stable and produce ultra-realistic images (e.g., Stable Diffusion).
Two-Stage Process
1. Forward Diffusion Process
Gradually add Gaussian noise to data:
At the end, images become pure noise.
2. Reverse Diffusion Process
A neural network learns to reverse the process:

Advantages of Diffusion Models
- High-quality, sharp outputs
- More stable than GANs
- Flexible: can do inpainting, editing, super-resolution
Popular Models
- DDPM (Denoising Diffusion Probabilistic Model)
- DDIM (faster sampling)
- Stable Diffusion (latent diffusion)
Simplified Denoising Step
def reverse_diffusion_step(x_t, t, model):
predicted_noise = model(x_t, t)
alpha_t = get_alpha(t)
noise = torch.randn_like(x_t)
x_prev = (1 / torch.sqrt(alpha_t)) * (
x_t - ((1 - alpha_t) /
torch.sqrt(1 - get_cumulative_alpha(t))) *
predicted_noise
) + torch.sqrt(1 - alpha_t) * noise
return x_prev21. What is the role of Transformers in NLP tasks?
Transformers in NLP
Transformers, introduced by Vaswani et al. (2017) in “Attention Is All You Need”, completely transformed NLP by replacing recurrent models such as RNNs and LSTMs.
Their key innovation is the self-attention mechanism, which allows the model to understand relationships between words regardless of their distance in the sequence.
Role of Transformers in NLP Tasks
1. Language Modeling
- GPT, GPT-2, GPT-3, etc.
- Predict the next token in a sequence (autoregressive modeling).
2. Machine Translation
- Encoder–decoder Transformers translate text between languages.
- Example: T5, mBART.
3. Text Summarization
- Models like BART, T5, Pegasus summarize long documents.
4. Question Answering
- BERT-based models extract answers from passages.
5. Sentiment Analysis / Classification
- Fine-tuned Transformers classify emotions, topics, or sentiments.
6. Named Entity Recognition (NER)
- Identify person names, organizations, dates, etc.
7. Text Generation / Conversational AI
- GPT-based models generate human-like responses.
8. Transfer Learning
Large pre-trained models (BERT, T5, GPT) are fine-tuned on downstream tasks with small datasets, enabling:
- Higher accuracy
- Less data requirement
- Faster development
Advantages of Transformers in NLP
| Feature | Benefit |
|---|---|
| Parallelizable | Removes sequential bottleneck, trains faster than RNNs |
| Self-attention | Captures long-range dependencies effectively |
| Scales to large models | Enables billions-parameter models like GPT-4 |
| Universal | Works for text, images, audio, and multimodal tasks |
22. Explain the concept of Masked Language Modeling (MLM).
Definition
Masked Language Modeling (MLM) is a pre-training objective used in bidirectional Transformer models such as BERT.
The idea is to hide (mask) some tokens in the input and train the model to predict the missing words using the surrounding context.
How MLM Works
- Randomly select 15% of tokens in the input sequence.
- Replace them with:
- [MASK] token (80% of the time)
- A random token (10% of the time)
- The original token (10% of the time)
- The model attempts to predict the original tokens at the masked positions.
Example
Input:"The [MASK] sat on the [MASK]."
Model predicts:
- cat
- mat
Why MLM is Important
- BERT learns bidirectional context, meaning it looks at both left and right words.
- Unlike GPT (which is left-to-right), BERT learns deeper semantic understanding.
- Enables strong performance in:
- Question answering
- Sentiment analysis
- Text classification
- Named entity recognition
Objective Function

Code Example (HuggingFace Transformers)
from transformers import BertTokenizer, BertForMaskedLM
import torch
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForMaskedLM.from_pretrained('bert-base-uncased')
text = "The cat sat on the [MASK]."
inputs = tokenizer(text, return_tensors='pt')
mask_token_index = torch.where(
inputs["input_ids"][0] == tokenizer.mask_token_id
)[0]
with torch.no_grad():
outputs = model(**inputs).logits
predicted_token_id = outputs[0, mask_token_index].argmax(dim=-1)
print(tokenizer.decode(predicted_token_id)) # Output: "mat"✅ 23. What is BERT, and how does it differ from GPT?
BERT (Bidirectional Encoder Representations from Transformers)
- Encoder-only architecture
- Uses Masked Language Modeling (MLM) + Next Sentence Prediction
- Learns bidirectional context (left + right)
GPT (Generative Pre-trained Transformer)
- Decoder-only architecture
- Uses Causal Language Modeling (CLM) → predicts next token
- Left-to-right context only
- Strong for text generation
Key Differences
| Feature | BERT | GPT |
|---|---|---|
| Architecture | Encoder-only | Decoder-only |
| Training | Masked LM | Causal LM |
| Context | Bidirectional | Unidirectional |
| Best For | Classification, QA | Text generation |
✅ 24. Describe the architecture and applications of T5.
T5 (Text-to-Text Transfer Transformer)
- Introduced by Google
- Converts every NLP task into text → text format
- Example:
"summarize: ..."→ summary
- Example:
- Based on Transformer Encoder-Decoder
Pre-training Task
- Uses Span Corruption
- Random spans replaced by a single mask token
- Model reconstructs missing text
Applications
- Summarization
- Translation
- Question Answering
- Sentiment Classification
- Paraphrasing
✅ 25. What is the significance of tokenization in NLP models?
Tokenization converts text → tokens → numeric IDs
Models cannot process text directly.
Why It Matters
- Determines vocabulary
- Handles unknown words
- Affects accuracy + efficiency
Types
- Word-level
- Subword tokenizers:
- BPE (GPT)
- WordPiece (BERT)
- Unigram (ALBERT)
- Character-level
Example
"unhappiness" → ["un", "happy", "##ness"] (WordPiece)
✅ 26. Explain the concept of attention mechanisms in NLP.
Attention Mechanism
Gives different importance (attention scores) to different tokens.
Self-Attention
Each token attends to all other tokens to learn relationships.
Formula
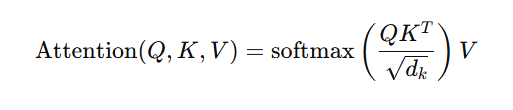
Example
In translation:
“dog” → “chien”
Model focuses on correct source word.
✅ 27. What are the challenges in training large-scale language models?
- High Computational Cost
- Requires multiple GPUs/TPUs
- Data Challenges
- Quality, bias, copyright
- Memory Limits
- Attention → O(n²)
- Interpretability
- Hard to understand internal reasoning
- Environmental Impact
- High carbon footprint
✅ 28. How do you fine-tune a pre-trained language model?
Steps
- Select Pre-trained Model (BERT, GPT-2, T5)
- Prepare Dataset
- Tokenize, create input-label pairs
- Add Task-Specific Head
- Classification → Linear layer over [CLS]
- Train
- AdamW, LR scheduler
- Evaluate and Save Checkpoint
✅ 29. What is the role of embeddings in NLP models?
Embeddings
Dense vector representations of words/subwords.
Role
- Capture meaning
- Allow models to understand similarity
- Replace sparse one-hot vectors
Types
- Word embeddings (Word2Vec, GloVe)
- Learned embeddings (BERT, GPT)
- Positional embeddings (Transformers)
✅ 30. Explain zero-shot learning in NLP.
Zero-Shot Learning
Model performs a task without training examples for that task.
Works Through:
- Strong pretraining
- Prompt engineering
- Language understanding
Example
Prompt:
“Translate to French: I love NLP”
Output:
“J’aime le traitement du langage naturel.”
Models
- GPT-3/4
- BART MNLI
- FLAN-T5
✅ 31. What is the role of GANs in image generation?
Role of GANs (Generative Adversarial Networks)
GANs are one of the most powerful methods for generating high-quality, realistic synthetic images.
How GANs Work
They consist of two networks trained in competition:
- Generator
- Takes random noise → generates realistic images.
- Goal: Fool the discriminator.
- Discriminator
- Classifies images as real or fake.
- Goal: Correctly identify fake images.
Key Capabilities
- Generate photorealistic images (e.g., StyleGAN)
- Conditional image generation (e.g., image from text or label)
- Style transfer, inpainting, domain translation (CycleGAN)
Applications
- Face and art synthesis
- Creating synthetic datasets
- Super-resolution
- Gaming and film industry
✅ 32. Explain the concept of style transfer in computer vision.
Style Transfer
A technique where the content of one image is combined with the style of another image.
Example:
Content of a photo + style of Van Gogh painting.
How It Works
Uses a pre-trained CNN (like VGG-19) to extract:
- Content features
- High-level representation (shapes, structure)
- Style features
- Texture & patterns using Gram matrices
Loss Function
Total loss = Content Loss + Style Loss
- Content Loss → MSE between content features
- Style Loss → MSE between Gram matrices of style image vs generated image
Optimization
- Start with content image
- Use gradient descent to update the generated image
- Minimize total loss
✅ 33. What is the significance of convolutional layers in image generation models?
Why Convolutional Layers Are Important
Convolutional layers (CNNs) are the backbone of image generation because they understand spatial structure.
Significance
- Capture hierarchical features (edges → textures → objects)
- Maintain spatial arrangement during upsampling/downsampling
- Efficient due to parameter sharing
- Learn local patterns (receptive fields)
Role in GANs
- Generator
- Uses transposed convolutions (deconvolutions) to convert noise → image
- Discriminator
- Uses standard convolutions to analyze image realism
Advantages
- Lower computation cost
- Better feature extraction
- Smooth and consistent image generation
✅ 34. Describe the architecture and applications of DeepDream.
DeepDream Overview
DeepDream, created by Google, visualizes what CNNs have learned by amplifying patterns inside neural networks.
Architecture
- Uses pre-trained CNNs (Inception, GoogLeNet)
- Instead of classifying, it modifies the input image itself
- Uses gradient ascent to enhance neural activations
How DeepDream Works
- Feed an image into the network
- Select a CNN layer whose features you want to amplify
- Compute gradients of activations w.r.t. the input image
- Update image to maximize those activations
- Repeat at multiple scales (octaves)
Applications
- Artistic image generation (psychedelic images)
- Visualizing CNN feature maps
- Understanding neural network biases
- Research in model interpretability
✅ 35. What are the challenges in generating high-resolution images?
High-resolution image synthesis (e.g., 1024×1024) is difficult due to:
| Challenge | Explanation |
|---|---|
| High computation cost | Needs large memory + GPU power |
| Training instability | GANs are difficult to stabilize |
| Mode collapse | Generator produces limited variety |
| Artifacts & distortions | Higher resolutions amplify errors |
| Evaluation difficulty | No perfect metric for image quality |
Solutions
- Progressive Growing GANs (train from low → high resolution)
- Multi-scale Discriminators
- Better losses (perceptual loss, Wasserstein loss)
- Regularization (spectral normalization, gradient penalty)
✅ 36. Explain the concept of super-resolution in image processing.
Super-Resolution (SR)
Super-resolution is the process of converting a low-resolution (LR) image into a high-resolution (HR) image by reconstructing or enhancing fine details.
Approaches
1. Traditional Methods
- Nearest-neighbor interpolation
- Bilinear / Bicubic interpolation
These are simple but produce blurry results.
2. Deep Learning Methods
Deep models learn LR → HR mapping:
- CNN-based models: SRResNet
- GAN-based models: ESRGAN, Real-ESRGAN
These generate sharp, detailed images by learning complex upsampling patterns.
Common Loss Functions
| Loss Type | Purpose |
|---|---|
| L1 / L2 (MSE) | Reconstruct pixel accuracy |
| Perceptual Loss | Uses VGG features → improves realism |
| Adversarial Loss | GAN loss → makes images photo-realistic |
✅ 37. What is the role of GANs in image-to-image translation?
Image-to-Image Translation
The task of converting an image from one domain to another, such as:
- Sketch → Photo
- Day → Night
- Black & White → Color
- Map → Satellite image
Role of GANs
GANs (especially conditional GANs) learn mappings between two domains.
- Generator: Learns function G(x)=yG(x) = yG(x)=y
- Discriminator: Checks if output image is realistic given input.
GANs guide the generator to produce realistic and sharp images.
Popular Models
- pix2pix → requires paired images
- CycleGAN → works with unpaired images
Applications
- Weather/season translation
- Aging/face transformation
- Colorization
- Photo restoration
✅ 38. Describe the architecture and applications of CycleGAN.
CycleGAN Overview
CycleGAN enables unpaired image-to-image translation—no need for matching image pairs.
Architecture
Consists of 2 Generators and 2 Discriminators:
- G : X → Y (e.g., Horse → Zebra)
- F : Y → X (Zebra → Horse)
- Dₓ: Distinguishes real X from fake X
- Dᵧ: Distinguishes real Y from fake Y
Loss Functions
- Adversarial Loss
Makes generated images look real in the target domain. - Cycle Consistency Loss
Ensures:
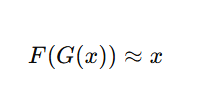
- This forces content preservation.
- Identity Loss (optional)
Helpful when color/style must be preserved.
Applications
- Summer ↔ Winter scenery
- Horses ↔ Zebras
- Monet Painting ↔ Photos
- Day ↔ Night
- Artistic transformations
✅ 39. What is the significance of the discriminator network in image generation?
Role of the Discriminator in GANs
The discriminator is crucial because it:
1. Provides Feedback to the Generator
- Acts as an adaptive loss function
- Helps generator create more realistic images
2. Prevents Mode Collapse
- Encourages generator to produce diverse images
- Penalizes repeated or identical outputs
3. Improves Image Quality
- Multi-scale or patch-based discriminators improve high-frequency details
Types of Discriminators
- Global Discriminator: Looks at the whole image
- PatchGAN: Classifies small patches (e.g., 70×70), useful for textures
- Multi-scale Discriminator: Used in StyleGAN, very effective for realism
✅ 40. Explain the concept of perceptual loss in image generation.
Perceptual Loss
Instead of comparing pixel-by-pixel, perceptual loss compares features extracted from a pre-trained CNN (like VGG19).
It prioritizes semantic similarity rather than exact pixel similarity.
Why It’s Important
| Pixel Loss (MSE) | Perceptual Loss |
|---|---|
| Produces blurry images | Produces sharp, realistic images |
| Penalizes small pixel shifts | Focuses on high-level features |
| No texture preservation | Preserves texture + structure |
How It Works
- Pass generated image and target image through a pre-trained CNN
- Extract intermediate feature maps (e.g., relu3_3, relu4_2)
- Compute MSE between these feature maps
Formula
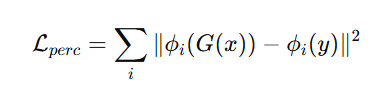
Where ϕᵢ are VGG feature maps.
41. What are the challenges in generating realistic audio?
Generating natural, human-like audio is difficult due to several technical challenges:
Key Challenges
| Challenge | Explanation |
|---|---|
| High Sampling Rate | Audio is sampled at 16k–48k Hz → extremely long sequences → models must process thousands of samples per second. |
| Temporal Coherence | Must maintain long-term patterns such as rhythm, phoneme transitions, and prosody. |
| Naturalness & Artifacts | Even small numerical errors cause robotic, metallic, or buzzy sound artifacts. |
| Speaker/Instrument Identity | Must preserve timbre, tone, accent, and style consistently. |
| High Computational Cost | Autoregressive models like WaveNet generate one sample at a time → slow. |
| Large Data Requirements | Needs high-quality, diverse audio datasets (speech, music, environmental sounds). |
Example
A generated voice may say correct words but sound unnatural due to incorrect pauses or intonation.
42. Describe the architecture and applications of WaveNet.
WaveNet Architecture (DeepMind, 2016)
WaveNet is an autoregressive deep neural network that generates raw audio sample-by-sample.
Key Components
- Dilated Causal Convolutions
- Preserve temporal order (no future leaks)
- Expand receptive field exponentially
- Gated Activation Units
- Control information flow (similar to LSTM gates)
- Softmax Output Layer
- Predicts next audio sample from a discrete distribution
Simple PyTorch-like Implementation Sketch
class DilatedCausalConv1d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, dilation):
super().__init__()
self.padding = (kernel_size - 1) * dilation
self.conv = nn.Conv1d(in_channels, out_channels, kernel_size,
padding=self.padding, dilation=dilation)
def forward(self, x):
return self.conv(x)[:, :, :-self.padding] # remove future padding
Applications
- Google Assistant (natural TTS)
- Music generation
- Audio super-resolution
- Voice conversion/cloning
- High-quality vocoders in modern TTS pipelines (Tacotron, FastSpeech, etc.)
43. What is the role of recurrent neural networks in audio generation?
Before Transformers and WaveNet, RNNs (LSTMs, GRUs) were widely used.
Roles in Audio Tasks
- Model temporal dependencies in speech and music
- Generate spectrograms or intermediate features
- Power early TTS models (e.g., Tacotron, Tacotron2)
- Sequence-to-sequence modeling for phoneme → mel-spectrogram conversion
Limitations
- Vanishing gradients → poor long-range memory
- Sequential operations → slow training and inference
- Hard to capture long-term musical structure
Example
An LSTM acoustic model generates mel-spectrograms from text, which are later converted to waveforms by a vocoder.
44. Explain the concept of text-to-speech (TTS) synthesis.
Text-to-Speech (TTS) converts written text into natural human speech.
TTS Pipeline
1. Text Preprocessing
- Normalization (“Dr.” → “Doctor”)
- Tokenization
- Phoneme conversion (optional)
- Stress & prosody handling
2. Acoustic Model
Converts text/phonemes → mel-spectrogram
Examples:
- Tacotron / Tacotron2
- Transformer TTS
- FastSpeech / FastSpeech2
3. Vocoder
Converts spectrogram → raw waveform
Models:
- WaveNet
- HiFi-GAN
- MelGAN
- WaveGlow
End-to-End TTS Models
- FastSpeech2
- Glow-TTS
- VITS
These skip the spectrogram and generate waveform directly.
Example (HuggingFace SpeechT5)
from transformers import SpeechT5Processor, SpeechT5ForTextToSpeech
import torch
processor = SpeechT5Processor.from_pretrained("microsoft/speecht5_tts")
model = SpeechT5ForTextToSpeech.from_pretrained("microsoft/speecht5_tts")
inputs = processor(text="Hello, this is a test sentence.", return_tensors="pt")
speech = model.generate_speech(inputs["input_ids"], speaker_embeddings)
45. What are the applications of generative models in music composition?
Generative AI is widely used in creative and professional music tasks.
Applications
| Use Case | Description |
|---|---|
| Melody Generation | Create new tunes, motifs, and musical ideas. |
| Style Transfer | Convert a song to jazz, classical, EDM; mimic composers. |
| Harmonization | Add chords to a melody automatically. |
| Drum/Rhythm Generation | Produce drum grooves, percussion lines. |
| Interactive Composition | Real-time improvisation (AI as a co-composer). |
| Sound Design | Generate new timbres, instruments, and textures. |
Examples
- Magenta Performance RNN — long-form piano performances
- OpenAI Jukebox — neural music with singing
- OpenAI MuseNet — multi-instrument compositions
- AIVA — film-score generation
✅ 46. Describe the architecture and applications of MuseNet.
MuseNet Overview
MuseNet is a Transformer-based generative music model developed by OpenAI capable of producing multi-instrument, multi-genre musical compositions.
Architecture
MuseNet is built on a GPT-style (decoder-only) Transformer, trained on MIDI data.
It learns:
- Harmony (chords, progressions)
- Rhythm (patterns, timing)
- Instrumentation (multiple instruments simultaneously)
- Genre Styles (classical, jazz, pop, rock)
- Long-range structure (up to ~4 minutes)
Key points:
- 72-layer Transformer
- Trained on a large MIDI corpus
- Learns both symbolic music + instrument embeddings
Capabilities
- Generates 4-minute compositions
- Supports 10+ instruments (piano, strings, drums, guitar, etc.)
- Performs style transfer (e.g., Mozart → jazz style)
- Creates coherent long-range musical structure
Applications
- Creative assistance for composers & producers
- Automatic background music for videos, games, ads
- Music style transfer & experimentation
- Educational tools for music theory and composition
- Generating variations on existing musical themes
✅ 47. What is the significance of attention mechanisms in audio generation?
Attention mechanisms allow models to focus on relevant parts of the input while generating audio.
They remove the need for explicit alignment and improve long-range modeling.
Why Attention is Important
- Aligns input text with output spectrogram/audio
- Handles long sequences better than RNNs
- Improves sound quality and pronunciation
- Enables stable mel-spectrogram generation
Types of Attention
| Type | Purpose |
|---|---|
| Soft Attention | Continuous and differentiable alignment (Tacotron). |
| Hard Attention | Stochastic, sparse selection of frames. |
| Self-Attention | Captures long-range relationships in audio (Transformers, Jukebox). |
Use Cases
- TTS (Tacotron, Transformer TTS)
Aligns phonemes with spectrogram frames (e.g., “he-llo” → correct timing) - Music generation
Tracks long-term note dependencies across measures - Audio-to-audio tasks
Noise removal, source separation
Example
In Tacotron, attention helps the model identify which word or phoneme corresponds to each output frame of the spectrogram, enabling natural speech.
✅ 48. Explain the concept of voice cloning using generative models.
Voice cloning = generating speech in a specific person’s voice, even from a few seconds of audio.
Three-Step Pipeline
1. Speaker Encoder
- Inputs a small voice sample (2–5 seconds)
- Outputs a speaker embedding capturing vocal identity:
- Pitch
- Timbre
- Accent
- Speaking style
2. TTS Acoustic Model
Converts:
text + speaker embedding → mel-spectrogram
Models used:
- Tacotron2
- FastSpeech2
- YourTTS
3. Neural Vocoder
Converts spectrogram → raw audio waveform.
Examples:
- HiFi-GAN
- WaveNet
- MelGAN
Popular Voice Cloning Systems
- YourTTS (zero-shot cloning)
- Real-Time Voice Cloning (RTVC)
- Resemblyzer (speaker embeddings)
- Meta TTS, VITS, etc.
Example Command (YourTTS)
python clone_voice.py --reference_audio reference.wav \
--text "This is my cloned voice" --output output.wav
✅ 49. What are the ethical considerations in generating synthetic audio?
Generative audio raises serious ethical concerns.
Key Ethical Issues
| Issue | Description |
|---|---|
| Misinformation & Deepfakes | Fake voices used to impersonate politicians, celebrities, etc. |
| Consent | Using someone’s voice without their permission is unethical & illegal. |
| Bias | Models inherit biases from datasets—accent bias, gender bias. |
| Copyright | Who owns the AI-generated speech or music? |
| Fraud & Scams | Voice cloning used for phone scams, financial fraud, kidnapping hoaxes. |
| Exploitation vs Accessibility | AI voices help disabled users but may replace voice actors. |
Mitigation Strategies
- Add watermarks or detectable markers to synthetic audio.
- Label AI-generated content clearly.
- Enforce strict consent policies for voice cloning.
- Develop ethical frameworks for use in media and AI tools.
✅ 50. Describe the applications of generative models in sound design.
Generative AI is transforming sound design across media, production, and digital creativity.
Applications
| Application | Description |
|---|---|
| Ambient Sound Generation | Creates nature atmospheres, rain, city noise, sci-fi environments. |
| Synth Patch Generation | Automatically generate new synthesizer tones & presets. |
| Game Audio | Procedural footsteps, explosions, fabric movement, weapon sounds. |
| Film Post-Production | ADR, Foley, background ambience, crowd noise. |
| Interactive Installations | AI reacts to motion, sensors, environment sounds. |
| Novel Instruments | Create new types of AI-driven instruments (e.g., NSynth). |
Popular Tools
- NSynth (Google Magenta): Neural audio synthesis via latent interpolation
- DDSP (Differentiable DSP): Hybrid DSP + ML sound generation
- DiffWave / DiffSinger: Diffusion-based audio models
- SoundDraw / Soundify: AI tools for creative sound generation
✅ 51. What are the ethical implications of generative AI?
Generative AI raises major ethical and societal risks due to its ability to create realistic synthetic content (images, audio, video, text).
Key Ethical Implications
| Issue | Description |
|---|---|
| Misinformation / Deepfakes | Fake videos, audio, or news can manipulate public opinion. |
| Privacy Violations | Models may unintentionally memorize faces, voices, or private text from training data. |
| Bias & Discrimination | Outputs may reflect harmful stereotypes present in training data. |
| Intellectual Property (IP) | Ownership ambiguity when AI generates content similar to copyrighted works. |
| Autonomous Weapons / Harmful Use | Generative AI can be misused for propaganda, targeting, scams. |
| Labor Displacement | Creative automation affects artists, writers, and designers. |
Example
A deepfake of a political leader making false statements can influence election outcomes—creating real-world danger.
✅ 52. How do you address bias in generative models?
Bias arises from training data, model design, and human-written prompts.
Sources of Bias
- Skewed or imbalanced datasets
- Historical stereotyping embedded in data
- Overrepresentation of certain demographic groups
- Model architecture unable to generalize fairly
Mitigation Strategies
| Strategy | Description |
|---|---|
| Data Auditing | Evaluate datasets for demographic balance. |
| Debiasing Techniques | Resampling, reweighting, or augmenting minority groups. |
| Fairness Constraints | Add fairness regularization to loss function. |
| Post-processing Filters | Remove biased or harmful outputs. |
| Diverse Prompt Engineering | Use inclusive wording to encourage fair responses. |
| Human-in-the-loop Review | Experts validate sensitive outputs. |
Code Example: Simple Prompt Filter
def filter_biased_prompts(prompt):
sensitive_topics = ["gender", "race", "religion"]
if any(topic in prompt.lower() for topic in sensitive_topics):
return f"Please revise your prompt to avoid sensitive topics: {', '.join(sensitive_topics)}."
return prompt
✅ 53. What is the concept of deepfakes, and how can they be detected?
Deepfakes
Deepfakes are synthetic media created using generative models (GANs, diffusion models) to impersonate real people.
Types of Deepfakes
- Face-swapping
- Lip-syncing
- Voice cloning
- Full-body generation (motion transfer)
- Synthetic humans
Deepfake Detection Techniques
| Method | Description |
|---|---|
| Forensic Analysis | Detect artifacts: inconsistent shadows, blinking, face edges, compression noise. |
| Metadata Analysis | Validate original timestamps, camera signatures. |
| AI-Based Classifiers | Train ML models to classify real vs fake images/videos. |
| Physiological Cues | Detect abnormal heartbeat, blinking patterns. |
| Watermarking / Cryptographic Signatures | Embed authenticity signatures in media. |
Tools
- Intel FakeCatcher (blood-flow detection)
- Adobe Content Credentials
- HuggingFace deepfake detection models
✅ 54. Explain the concept of model explainability in generative AI.
Model Explainability
Explainability refers to understanding why and how a generative model produces its outputs.
It is essential for:
- Bias detection
- Trust and transparency
- Debugging and improving models
- Ensuring safe decision-making
Explainability Techniques
| Technique | Description |
|---|---|
| Attention Visualization | Shows which input tokens/regions influenced the output. |
| Feature Attribution (SHAP, LIME) | Quantifies contribution of each input feature. |
| Counterfactual Explanations | “What change in input would alter the output?” |
| Latent Space Exploration | Interpolations reveal how features are encoded. |
| Neuron Activation Analysis | Measures semantic roles of hidden neurons. |
Example
In a GPT summary model, attention heatmaps show which sentences most influenced the generated summary.
✅ 55. What are the challenges in ensuring fairness in generative models?
Ensuring fairness is hard because generative models are trained on massive, uncurated datasets and produce open-ended outputs.
Key Challenges
| Challenge | Explanation |
|---|---|
| Defining Fairness | Fairness varies across cultures, domains, and contexts. |
| Data Representation | Minority groups may be underrepresented in training data. |
| Evaluation Metrics | Hard to measure fairness in free-form text or images. |
| Model Complexity | Models are black boxes; outputs hard to trace. |
| Dynamic Inputs (Prompts) | User prompts vary → unpredictable model behavior. |
| Unsupervised Learning | Models may pick up unwanted correlations. |
| Long-tail Bias | Rare classes often ignored or poorly generated. |
Solutions
- Establish clear fairness objectives per use-case.
- Use diverse and representative training datasets.
- Apply fairness-aware metrics such as demographic parity.
- Incorporate human oversight in sensitive domains.
- Build guardrails (filters, safety layers) for harmful content.
✅ 56. How do you handle adversarial attacks in generative models?
What Are Adversarial Attacks?
Small, intentionally designed changes to input (text, image, audio) that cause a generative model to behave incorrectly, unpredictably, or harmfully.
Types of Attacks
- Input-based attacks
- Slight changes to prompts/images/audio
- Goal: mislead the model into producing harmful or incorrect outputs
- Latent-space attacks
- Manipulating latent vectors during generation
- Can force the model to produce targeted, malicious results
- Model-level attacks
- Exploiting architecture weaknesses
- Backdoor triggers
Defense Mechanisms for Generative Models
| DEFENSE | DESCRIPTION |
|---|---|
| Adversarial (Robust) Training | Train on adversarial examples to increase resilience |
| Input Sanitization | Scan and clean suspicious prompts or images |
| Anomaly / OOD Detection | Identify inputs that lie outside normal training distribution |
| Model Monitoring | Continuous logging and output audit |
| Rate Limiting & Access Control | Prevent systematic probing of model boundaries |
Code Snippet — Detect OOD (Out-of-Distribution) Input
from sklearn.svm import OneClassSVM
# Train anomaly detector on embeddings of normal prompts
detector = OneClassSVM().fit(normal_prompt_embeddings)
# Predict whether new prompt is anomalous
if detector.predict([new_prompt_embedding]) == -1:
print("⚠️ Potential adversarial input detected!")
✅ 57. What is the role of transparency in generative AI systems?
Definition
Transparency means making the internal functioning, limitations, and training context of generative models understandable to users and regulators.
Components of Transparency
- Model Disclosure
Architecture, dataset sources, training procedure, limitations - Output Labeling
Marking AI-generated text/images/audio - Explainability Tools
Showing why a model produced a certain result - Open Documentation & Open Source
Public model cards, system cards, FactSheets
Benefits
- Builds user trust
- Ensures regulatory compliance
- Improves safety and accountability
- Enables research reproducibility
Examples of Transparency Initiatives
- Model Cards (Google)
- System Cards (HuggingFace)
- AI FactSheets (IBM)
✅ 58. How do you ensure accountability in generative AI?
Key Strategies
| STRATEGY | DESCRIPTION |
|---|---|
| Governance Policies | Assign roles for development, deployment, and risk management |
| Usage Logs | Track inputs/outputs to prevent misuse |
| Human-in-the-Loop | Humans review high-impact or sensitive outputs |
| Legal Compliance | GDPR, copyright laws, content regulations |
| User Training & Awareness | Educate users on model risks and limitations |
✔ Example
A news agency using generative AI must:
- Log all generated content
- Verify credibility
- Disclose AI usage
- Ensure a human editor reviews all published articles
✅ 59. What are the privacy concerns associated with generative models?
Major Privacy Risks
| ISSUE | DESCRIPTION |
|---|---|
| Memorization | Models may unintentionally reproduce personal training data |
| Re-identification | Generated samples can reveal identities from training sets |
| Voice/Face Cloning | AI-driven impersonation without consent |
| Surveillance Abuse | Used for large-scale monitoring (deepfake identification, etc.) |
Solutions
- Differential Privacy (noise in gradients prevents memorization)
- Membership Inference Defense
- Federated Training (avoid centralizing private data)
- Data Minimization & Consent
- Rate limiting + red-teaming
✅ 60. How do you address data poisoning in generative models?
What is Data Poisoning?
An attacker injects malicious or misleading samples into the training dataset to:
- Insert biased patterns
- Cause harmful generations
- Create model backdoors triggered by specific inputs
Mitigation Strategies
| STRATEGY | DESCRIPTION |
|---|---|
| Data Filtering & Cleaning | Remove low-quality or toxic samples |
| Trusted Data Sources | Use verified, curated datasets |
| Robust Training | Loss functions that reduce effect of outliers |
| Outlier/Anomaly Detection | Identify suspicious training entries |
| Model Watermarking | Detect if a model was trained on poisoned data |
Code Example — Filtering Toxic Samples
from detoxify import Detoxify
def filter_toxic_samples(dataset):
filtered = []
detector = Detoxify('original')
for sample in dataset:
toxicity = detector.predict(sample)['toxicity']
if toxicity < 0.5: # keep only clean samples
filtered.append(sample)
return filtered✅ 61. What are the challenges in deploying generative models in production?
Key Challenges
| CHALLENGE | DESCRIPTION |
|---|---|
| High Computational Cost | Large models (GPT-3, LLaMA, Stable Diffusion) require powerful GPUs/TPUs; inference is expensive. |
| Latency & Throughput Issues | Autoregressive models decode token-by-token → slow for long outputs. |
| High Memory Usage | Models with billions of parameters require multi-GB VRAM. |
| Model Serving Complexity | Need to manage APIs, scaling, load balancing, versioning, autoscaling. |
| Security & Privacy Risks | Possibility of misuse, prompt injection, data leakage, adversarial attacks. |
| Monitoring & Logging | Track model drift, hallucinations, bias, latency, and failures. |
| Cost Management | GPU cost spikes during traffic peaks; inefficiencies increase cloud bills. |
| Regulatory & Compliance Issues | Must meet GDPR, copyright, transparency requirements. |
Example
Deploying a real-time Stable Diffusion image generation API is expensive without:
- Model quantization
- GPU batching
- Caching
- Distributed inference
✅ 62. How do you optimize the performance of generative models?
Common Optimization Techniques
| TECHNIQUE | DESCRIPTION |
|---|---|
| Batch Processing | Generate multiple samples at once to better utilize GPU. |
| Caching | Save common outputs/prompts to reduce repetitive computation. |
| Parallelism | Multi-GPU, tensor parallelism, or pipeline parallelism. |
| Efficient Decoding | Top-k, top-p (nucleus sampling), beam search, speculative decoding. |
| Model Compression | Quantization, pruning, distillation reduce size & speed up inference. |
| ONNX / TensorRT Optimization | Convert models for optimized runtime inference. |
| Lazy Loading & Sharding | Load only required layers into memory. |
Code Example — Batched Text Generation (HuggingFace)
from transformers import pipeline
generator = pipeline("text-generation", model="gpt2")
prompts = ["Once upon a time",
"In the future",
"The quick brown fox"]
# Efficient batched inference
outputs = generator(prompts, batch_size=4)
print(outputs)
✅ 63. What is the role of model quantization in deployment?
Model Quantization
Reducing the precision of model parameters, e.g.:
- FP32 → FP16 → INT8 → INT4 → INT2
Benefits
- Reduced model size (up to 4× smaller)
- Lower GPU/CPU memory usage
- Faster inference (20–300% speed-up)
- Enables running large models on edge devices
Tools & Frameworks
- HuggingFace Transformers (bitsandbytes / GPTQ quantization)
- ONNX Runtime (INT8 inference)
- NVIDIA TensorRT
- GGUF models for LLaMA / Mistral
Example — Running a Quantized LLaMA Model (GPTQ)
python main.py --model llama --quantize --precision int4
✅ 64. Explain the concept of model pruning in generative models.
Model Pruning
Removing redundant weights, neurons, or attention heads to:
- reduce size
- increase speed
- lower inference cost
Types of Pruning
| TYPE | DESCRIPTION |
|---|---|
| Structured Pruning | Remove entire layers, attention heads, or channels; hardware-friendly. |
| Unstructured Pruning | Remove individual weights; results in sparse matrices. |
Impact
- Can reduce model size by 60–90% with minimal accuracy loss.
- Useful for:
- mobile deployment
- low-power inference
- faster transformer layers
Code Example — PyTorch Unstructured Pruning
import torch.nn.utils.prune as prune
# Prune 50% of weights in a linear attention layer
prune.l1_unstructured(
model.transformer.h[0].attn.c_attn,
name='weight',
amount=0.5
)
✅ 65. How do you handle large-scale data in generative AI applications?
Key Strategies
| STRATEGY | DESCRIPTION |
|---|---|
| Distributed Training | Use PyTorch Distributed, DeepSpeed, Horovod for multi-GPU/TPU training. |
| Data Sharding | Split dataset across machines to avoid memory overload. |
| Streaming Datasets | Load only required samples at runtime (WebDataset, HF streaming). |
| Data Curation | Remove toxic, harmful, duplicate, or irrelevant data. |
| Efficient Storage Formats | Use TFRecords, LMDB, Parquet, Arrow for fast loading. |
| Parallel I/O Pipelines | Pre-fetch and cache data batches to avoid CPU bottlenecks. |
HuggingFace Streaming Example
from datasets import load_dataset
# Stream large dataset without loading fully into memory
ds = load_dataset(
'wikipedia',
'20220301.en',
split='train',
streaming=True
)
for item in ds.take(3):
print(item)
Streaming avoids RAM overflow and speeds up training pipelines.
✅ 66. Considerations for Deploying Generative Models on Edge Devices
| FACTOR | DESCRIPTION |
|---|---|
| Model Size | Must fit in limited storage (MBs) and RAM; large Transformer models may need quantization or pruning. |
| Power Consumption | Battery-powered devices require energy-efficient inference (FP16/INT8, lightweight models). |
| Latency Requirements | Real-time tasks (voice assistants, AR/VR) need low-latency inference. |
| Security | Protect models from extraction or tampering on untrusted devices. |
| Model Compatibility | Must support edge frameworks: TensorFlow Lite, ONNX Runtime, PyTorch Mobile. |
Example:
Running FastSpeech2 + MelGAN on a smartphone for offline text-to-speech without cloud dependency.
✅ 67. Ensuring Scalability of Generative AI Systems
| APPROACH | DESCRIPTION |
|---|---|
| Horizontal Scaling | Add more servers/nodes to handle higher traffic. |
| Load Balancing | Distribute incoming requests evenly across replicas. |
| Auto-Scaling | Dynamically scale infrastructure based on traffic spikes. |
| Caching Layers | Use Redis/Memcached for frequently requested prompts/outputs. |
| Microservices Architecture | Break the system into independent services (e.g., model inference, logging, API gateway). |
Example — AWS Auto Scaling Group (YAML snippet)
Resources:
MyAutoScalingGroup:
Type: AWS::AutoScaling::AutoScalingGroup
Properties:
MinSize: "1"
MaxSize: "10"
DesiredCapacity: "2"
LaunchConfigurationName: !Ref MyLaunchConfig
✅ 68. Role of Containerization in Deploying Generative Models
| BENEFIT | DESCRIPTION |
|---|---|
| Portability | Run the same environment across development, staging, and production. |
| Isolation | Prevent dependency conflicts between models or services. |
| Version Control | Track changes in Docker images for reproducibility. |
| CI/CD Integration | Automate testing, deployment, and rollback in pipelines. |
Popular Tools:
- Docker (packaging and lightweight containers)
- Kubernetes (orchestration, scaling, deployment)
Dockerfile Example (FastAPI + GPT Model)
FROM python:3.10-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install -r requirements.txt
COPY . .
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "80"]
✅ 69. Monitoring the Performance of Generative Models in Production
| METRIC | DESCRIPTION |
|---|---|
| Latency | Time taken per request; measure response speed. |
| Throughput | Requests processed per second; indicates system capacity. |
| GPU/CPU Utilization | Monitor compute usage for optimization. |
| Output Quality | BLEU, ROUGE, METEOR, or human evaluation for generated text/images. |
| Error Rate | Track failed or malformed requests. |
| Drift Detection | Monitor changes in input/output distributions over time. |
Tools:
- Prometheus + Grafana → Real-time metric visualization
- Elasticsearch + Kibana → Log aggregation and search
- Weights & Biases / MLflow → Experiment tracking and model performance history
✅ 70. Strategies for Updating Generative Models in Production
| STRATEGY | DESCRIPTION |
|---|---|
| A/B Testing | Serve two versions to compare performance on real users. |
| Canary Release | Gradually roll out new model to a small subset before full deployment. |
| Blue-Green Deployment | Maintain two environments (blue/green); switch traffic after validation. |
| Hot Swapping | Replace model weights or versions without restarting server. |
| Rollback Mechanisms | Revert to previous model version if new version underperforms or fails. |
Example — Kubernetes Blue-Green Deployment (YAML snippet)
apiVersion: apps/v1
kind: Deployment
metadata:
name: gpt-model-green
spec:
replicas: 3
selector:
matchLabels:
app: gpt-api
version: green
# Gradually shift traffic from blue to green deployment
Key Point: Blue-Green + Canary together ensures minimal downtime and safe model updates.
✅ 71. Generative AI in Content Creation
Overview:
Generative AI automates the creation of digital content, helping writers, designers, marketers, and educators produce high-quality material efficiently.
Use Cases:
| AREA | DESCRIPTION |
|---|---|
| Copywriting | Generate blog posts, product descriptions, ad copy, social media content. |
| Visual Design | Create illustrations, logos, banners, infographics using models like DALL·E, MidJourney. |
| Audio/Video | Produce voiceovers (Descript), synthetic videos (Synthesia), or background music. |
| Creative Assistance | Help authors with plot ideas, storylines, or character development. |
Example Tools: Jasper, Copy.ai, Runway ML
✅ 72. Applications of Generative Models in Healthcare
Overview:
Generative models support healthcare by augmenting datasets, simulating scenarios, and creating synthetic data while preserving privacy.
Applications:
| AREA | DESCRIPTION |
|---|---|
| Medical Imaging | Generate rare pathologies in CT/MRI scans for training diagnostic models. |
| Patient Data Augmentation | Produce realistic synthetic patient records to preserve privacy. |
| Disease Simulation | Model progression of diseases under different conditions. |
| Drug Response Prediction | Simulate patient responses to treatments. |
Techniques & Tools:
- GANs: CT/MRI image generation
- VAEs: Patient trajectory simulation
✅ 73. Role of Generative AI in Drug Discovery
Overview:
Accelerates drug design by generating novel molecules, optimizing properties, and exploring chemical space efficiently.
Key Applications:
| APPLICATION | DESCRIPTION |
|---|---|
| Molecular Generation | Create novel molecules with specific therapeutic targets. |
| Property Optimization | Improve solubility, bioavailability, and reduce toxicity. |
| Hit Discovery | Screen large chemical libraries efficiently. |
| De Novo Design | Design entirely new compounds from scratch. |
Techniques:
- Graph-based GANs and VAEs
- Transformers on SMILES strings
Companies Using This: Insilico Medicine, Atomwise, BenevolentAI
✅ 74. Generative AI in Fashion Design
Overview:
AI assists designers in creating new clothing designs, patterns, and virtual try-ons, reducing physical prototyping costs.
Use Cases:
| AREA | DESCRIPTION |
|---|---|
| Design Assistance | Generate outfit variations or concept designs from sketches or trends. |
| Virtual Try-On | Use image-to-image translation to visualize clothing on users. |
| Fabric Pattern Generation | Create unique prints and textures. |
| Sustainable Fashion | Reduce material waste via digital prototyping. |
Examples:
- Stable Diffusion: Fashion illustrations
- Zalando + DeepFashion: Pose-conditioned image generation
✅ 75. Applications of Generative Models in Gaming
Overview:
Enhances game development and player experiences by generating dynamic content automatically.
Applications:
| AREA | DESCRIPTION |
|---|---|
| Procedural Level Design | Automatically generate maps, terrains, or dungeons. |
| Character/NPC Generation | Create diverse player characters and NPCs. |
| Dialogue Generation | LLMs provide adaptive NPC dialogue and interactions. |
| Game Assets Generation | Automate creation of textures, animations, sounds. |
Examples:
- AI Dungeon: LLM-driven narrative text adventures
- NVIDIA GameGAN: Learned to recreate Pac-Man gameplay environment without explicit code
✅ 76. Generative AI in Virtual Reality (VR)
Overview:
Generative AI enhances immersion, interactivity, and realism in VR environments by automatically creating content and behaviors.
Applications:
| AREA | DESCRIPTION |
|---|---|
| Environment Generation | Automatically generate immersive 3D worlds, terrains, and landscapes. |
| Avatar Creation | Generate realistic or personalized avatars from photos, sketches, or textual descriptions. |
| Realistic Dialogue & Behavior | Power intelligent NPCs and virtual agents with lifelike responses. |
| Dynamic Storytelling | Adapt narratives in real time based on user actions or interactions. |
Tools & Platforms:
- Meta Avatars SDK
- Unity + HuggingFace integration (for AI-driven dialogue systems)
✅ 77. Generative AI in Autonomous Vehicles
Overview:
Supports perception, simulation, and safety testing for autonomous vehicles.
Applications:
| AREA | DESCRIPTION |
|---|---|
| Data Augmentation | Generate rare or extreme driving scenarios (accidents, bad weather). |
| Simulated Testing | Train models in virtual environments before deployment on real roads. |
| Sensor Fusion & Anomaly Detection | Enhance reliability of object detection across multiple sensors. |
| Predictive Modeling | Forecast pedestrian movements, traffic patterns, or road hazards. |
Techniques:
- Conditional GANs for synthetic sensor data
- Diffusion models for adverse weather simulations
✅ 78. Generative AI in Robotics
Overview:
Helps robots learn, adapt, and operate efficiently in diverse environments with minimal real-world data.
Applications:
| AREA | DESCRIPTION |
|---|---|
| Motion Planning | Generate smooth, collision-free paths for robotic arms and manipulators. |
| Task Learning | Learn complex behaviors from a few demonstrations or examples. |
| Simulation Training | Train robots in virtual environments before real-world deployment. |
| Human-Robot Interaction | Interpret natural language commands or gestures using AI models. |
Techniques:
- Reinforcement learning with generative world models
- Imitation learning via sequence modeling
✅ 79. Generative AI in Education
Overview:
Improves personalization, automates content creation, and enhances interactive learning experiences.
Applications:
| AREA | DESCRIPTION |
|---|---|
| Personalized Tutoring | AI tutors adapt to student learning styles and pace. |
| Content Creation | Generate quizzes, lesson plans, diagrams, and exercises. |
| Automated Grading | Evaluate essays, coding assignments, or short-answer questions. |
| Interactive Learning | Build chatbots, simulations, and gamified learning experiences. |
Tools:
- Socratic (Google) – Visual explanations for math problems
- Carnegie Learning – Adaptive tutoring platforms
✅ 80. Generative AI in Marketing & Advertising
Overview:
Automates creative workflows, personalizes content, and enhances customer engagement.
Applications:
| AREA | DESCRIPTION |
|---|---|
| Ad Copy Generation | Create multiple versions of advertisements targeting different demographics. |
| Product Visualization | Generate lifestyle images of products in different contexts or settings. |
| Email Personalization | Customize email content at scale for individual recipients. |
| Customer Chatbots | Provide 24/7 support using AI-driven conversational agents. |
Tools & Platforms:
- Copy.ai, Jasper, AdCreative.ai
- MidJourney, DALL·E (for visuals)
Code Example (Generating Email Variants):
from transformers import pipeline
generator = pipeline("text-generation", model="gpt2")
prompt = "Hi [Name], we're excited to offer you a special discount on our new product!"
variants = generator(prompt, num_return_sequences=5)
for i, variant in enumerate(variants):
print(f"Variant {i+1}:")
print(variant['generated_text'])
print("---")✅ 81. Popular Frameworks for Developing Generative Models
| FRAMEWORK | DESCRIPTION |
|---|---|
| PyTorch | Flexible dynamic computation graph; widely used in research and prototyping. |
| TensorFlow / Keras | Static/dynamic computation graphs; strong production support. |
| JAX | High-performance numerical computing with automatic differentiation and JIT compilation. |
| Hugging Face Transformers | Library of pre-trained models (GPT, BERT, T5, etc.) for NLP and multimodal generation. |
| FastGAN / StyleGAN / CycleGAN | Specialized GAN implementations for image synthesis. |
| Diffusers (Hugging Face) | Library for state-of-the-art diffusion models. |
| ONNX | Standard for cross-framework model compatibility and deployment. |
Use Cases:
- Research: PyTorch, JAX
- Production: TensorFlow, ONNX + TensorRT
- Easy deployment: Hugging Face Transformers
✅ 82. Role of TensorFlow in Generative AI
Overview:
TensorFlow, developed by Google, is a versatile framework for building, training, and deploying generative models.
Key Features:
- Eager Execution (TF2): Debug like PyTorch.
- tf.keras: High-level API for model building.
- tf.data: Efficient data pipelines for large datasets.
- SavedModel & TF Serving: Scalable model deployment.
- TPU Support: Optimized for cloud training.
Example: GAN Generator (TensorFlow/Keras)
import tensorflow as tf
from tensorflow.keras import layers
def build_generator(latent_dim):
model = tf.keras.Sequential([
layers.Dense(128, activation='relu', input_shape=(latent_dim,)),
layers.Dense(784, activation='tanh')
])
return model
✅ 83. How PyTorch Supports Generative Model Development
Overview:
PyTorch is favored for research due to its dynamic computation graph and intuitive design.
Key Features:
- TorchVision / TorchText / TorchAudio: Data loading and preprocessing.
- nn.Module: Easy to subclass for custom models.
- Distributed Training: Multi-GPU and multi-node support.
- TorchScript: Export models for deployment.
Example: Simple VAE in PyTorch
import torch
import torch.nn as nn
class VAE(nn.Module):
def __init__(self, latent_dim=20):
super().__init__()
self.encoder = nn.Linear(784, 400)
self.mu = nn.Linear(400, latent_dim)
self.log_var = nn.Linear(400, latent_dim)
self.decoder = nn.Linear(latent_dim, 784)
def reparameterize(self, mu, log_var):
std = torch.exp(0.5 * log_var)
eps = torch.randn_like(std)
return mu + eps * std
def forward(self, x):
h = torch.relu(self.encoder(x))
mu = self.mu(h)
log_var = self.log_var(h)
z = self.reparameterize(mu, log_var)
return self.decoder(z), mu, log_var
✅ 84. Significance of JAX in Generative AI Research
Overview:
JAX combines NumPy-like syntax with automatic differentiation and high-performance compilation, ideal for research.
Advantages:
- Speed: XLA compiler accelerates GPU/TPU training.
- Composable Transformations:
grad,vmap,pmapsimplify operations. - Functional Programming: Encourages pure, testable functions.
Use Cases:
- Diffusion models, fast prototyping, research experiments.
Example: Gradient Descent in JAX
import jax.numpy as jnp
from jax import grad
def loss(w):
return (w - 5)**2
grad_loss = grad(loss)
update = lambda w, step_size: w - step_size * grad_loss(w)
w = 0.0
for i in range(100):
w = update(w, 0.1)
print(f"Optimized weight: {w}")
✅ 85. Role of Hugging Face in Generative AI
Overview:
Hugging Face provides pre-trained models, datasets, and infrastructure for NLP and multimodal generative AI.
Key Components:
- Transformers Library: Thousands of pre-trained models.
- Datasets Library: Stream, preprocess, and manage datasets.
- Spaces: Host demos and interactive applications.
- Diffusers Library: State-of-the-art diffusion models (DDPM, DDIM, LDM).
- Inference API: Deploy models without building servers.
Example: Using Pretrained GPT
from transformers import pipeline
generator = pipeline("text-generation", model="gpt2")
result = generator("Once upon a time", max_length=50)
print(result[0]["generated_text"])✅ 86. Using Pre-Trained Models in Generative AI
Steps to Use Pre-Trained Models:
- Select a Model: HuggingFace, TensorFlow Hub, or official repositories.
- Load Weights: Use
from_pretrained()or native format loaders. - Fine-Tune: Adapt to domain-specific data if necessary.
- Deploy: Serve via REST APIs, mobile apps, or embedded systems.
Code Example (Summarization using HuggingFace T5):
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, pipeline
tokenizer = AutoTokenizer.from_pretrained("t5-small")
model = AutoModelForSeq2SeqLM.from_pretrained("t5-small")
summarizer = pipeline("summarization", model=model, tokenizer=tokenizer)
summary = summarizer(
"This is a long article about AI ethics and its impact on society, including privacy, bias, and accountability...",
max_length=50
)
print(summary[0]["summary_text"])
Sample Output:
AI ethics is important for privacy, bias, and accountability in society.
✅ 87. Considerations for Selecting a Framework
| FACTOR | EXPLANATION |
|---|---|
| Research vs Production | PyTorch preferred for research; TensorFlow for production deployments. |
| Ease of Use | High-level APIs: Keras, HuggingFace pipelines simplify development. |
| Community & Ecosystem | PyTorch has strong academic support; TensorFlow widely used in industry. |
| Performance & Speed | JAX provides JIT-compiled high-performance operations. |
| Deployment Tools | TensorFlow Serving, TorchScript, ONNX enable scalable deployment. |
| Hardware Support | GPU/TPU availability differs by framework. |
| Customization Needs | Dynamic graphs (PyTorch) offer flexibility for custom architectures. |
✅ 88. Implementing Custom Loss Functions
In PyTorch (e.g., VAE Loss):
import torch
import torch.nn as nn
class CustomLoss(nn.Module):
def __init__(self):
super().__init__()
def forward(self, recon_x, x, mu, logvar):
BCE = nn.functional.binary_cross_entropy(recon_x, x, reduction='sum')
KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
return BCE + KLD
In TensorFlow (VAE Loss):
import tensorflow as tf
def custom_vae_loss(y_true, y_pred, z_mean, z_log_var):
reconstruction_loss = tf.reduce_mean(tf.square(y_true - y_pred))
kl_loss = -0.5 * tf.reduce_mean(1 + z_log_var - tf.square(z_mean) - tf.exp(z_log_var))
return reconstruction_loss + kl_loss
✅ 89. Role of Cloud Platforms in Deployment
| PLATFORM | ROLE |
|---|---|
| AWS SageMaker | Train and deploy models at scale. |
| Google Vertex AI | AutoML, hyperparameter tuning, serving. |
| Azure ML Studio | Visual interface with Azure ecosystem integration. |
| HuggingFace Inference Endpoints | Fast deployment of transformer models. |
| RunPod / Lambda Labs | Affordable GPU/TPU instances for small teams. |
Benefits:
- Scalable compute resources (GPU/TPU).
- Managed inference endpoints.
- CI/CD pipelines integration.
- Monitoring and logging capabilities.
✅ 90. Using GPUs for Training Generative Models
Key Concepts:
- CUDA Cores: Parallel units on NVIDIA GPUs.
- cuDNN: Optimized deep learning primitives.
- Mixed Precision Training: FP16 + FP32 for faster training.
Enable GPU in PyTorch:
import torch
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
data = data.to(device)
Training Loop with GPU:
for epoch in range(epochs):
for batch in dataloader:
inputs = batch.to(device)
outputs = model(inputs)
loss = loss_function(outputs, inputs)
optimizer.zero_grad()
loss.backward()
optimizer.step()
Output Example:
Epoch 1/10, Batch 1, Loss: 0.435
Epoch 1/10, Batch 2, Loss: 0.421
...
Epoch 10/10, Batch N, Loss: 0.128
Explanation: GPU accelerates matrix operations, reducing training time for large models significantly.
✅ 91. Emerging Trends in Generative AI
| TREND | DESCRIPTION |
|---|---|
| Multimodal Generation | Models generate across text, images, audio simultaneously (e.g., DALL·E, CLIP, Flamingo). |
| Few-Shot & Zero-Shot Learning | Models can perform new tasks with minimal or no task-specific examples. |
| Diffusion Models Dominate | Stable and high-quality image/audio generation surpassing GANs (e.g., Stable Diffusion). |
| Model Compression & Efficiency | Techniques like quantization and distillation enable deployment on edge devices. |
| LLMs as APIs | Accessing large language models via cloud services (OpenAI, Anthropic, Google). |
| AI Agents with Memory & Planning | Combining LLMs with tools, memory, and planning modules for goal-directed tasks. |
| Ethical & Regulatory Guardrails | Watermarking, bias detection, and explainability frameworks for responsible AI use. |
✅ 92. Reinforcement Learning (RL) Integration with Generative Models
Concept:
- RL is used when generation should optimize long-term objectives rather than immediate likelihood.
Applications:
- Dialogue Systems → Encourage coherent, engaging conversations.
- Code Generation → Reward functional, bug-free programs.
- Music Composition → Reward harmonic and rhythmic consistency.
Approach:
- RLHF (Reinforcement Learning from Human Feedback):
- Train a reward model on human preferences.
- Fine-tune generator using PPO or other RL algorithms.
Example (Pseudocode):
def train_with_rl(model, reward_model):
while not done:
prompt = get_prompt()
response = model.generate(prompt)
reward = reward_model(prompt, response)
model.update_policy(reward)
✅ 93. Few-Shot Learning in Generative AI
Concept:
- Allows models to learn new tasks from a few examples provided at inference time, without full retraining.
Mechanism:
- Large LLMs (e.g., GPT-3/4) extract patterns from examples included in the prompt.
Example Prompt:
Input: Apple -> AAPL
Microsoft -> MSFT
Google -> ?
Output: GOOG
Use Cases:
- Custom classification tasks.
- Code generation from small examples.
- Translation in low-resource languages.
✅ 94. Future of Generative AI in Creative Industries
| DOMAIN | IMPACT |
|---|---|
| Art & Design | Assist with ideation, style transfer, and variations. |
| Music | Generate melodies, harmonies, remixes. |
| Film & Animation | Storyboards, character design, synthetic actors. |
| Writing & Journalism | Draft articles, scripts, dialogue. |
| Fashion & Architecture | Rapid prototyping and visualization. |
Trends:
- Collaborative Creativity: AI acts as a creative assistant rather than replacement.
- New Art Forms: Generative NFTs, AI-driven performances, and interactive stories.
✅ 95. Challenges in Achieving General Artificial Intelligence (AGI)
| CHALLENGE | EXPLANATION |
|---|---|
| Common Sense Reasoning | Models lack world knowledge and logical understanding. |
| Transfer Learning Limitations | Poor generalization across different domains. |
| Memory & Continuity | Hard to retain context over long sequences or interactions. |
| Understanding vs Mimicry | Current models mimic patterns without true comprehension. |
| Evaluation Metrics | No standardized way to measure AGI progress. |
| Computational Limits | Training massive models is resource-intensive and costly. |
Research Directions:
- Hybrid symbolic-AI approaches for reasoning.
- World models and embodied AI for interaction with environments.
- Self-supervised learning combined with physical interaction.
✅ 96. Generative AI and the Job Market
| ASPECT | EFFECT |
|---|---|
| Content Creation | Automates writing, design, video editing. |
| Customer Service | Chatbots handle basic support roles. |
| Programming | Assists developers with code suggestions and debugging. |
| Education | Personalized tutoring and content generation. |
| Legal & Finance | Drafting documents, compliance checks. |
| Creative Professions | Augments, rather than replaces, artists, designers, writers. |
Potential Risks:
- Displacement of repetitive jobs.
- Increased demand for reskilling and upskilling.
✅ 97. Ethical Considerations for Future Generative AI
| ISSUE | DESCRIPTION |
|---|---|
| Misinformation / Deepfakes | Synthetic content used for deception. |
| Bias & Discrimination | Reinforces societal inequalities. |
| Privacy Violations | Voice cloning, face generation without consent. |
| Intellectual Property | Ownership unclear for AI-generated derivative works. |
| Autonomous Harm | Disinformation campaigns, malware generation. |
| Environmental Impact | Energy-intensive training and inference. |
Mitigation Strategies:
- Transparency and disclosure.
- Watermarking synthetic media.
- Legal frameworks and audits for accountability.
✅ 98. Role of Generative AI in Scientific Research
| FIELD | APPLICATION |
|---|---|
| Biology | Protein folding (AlphaFold), drug discovery. |
| Chemistry | Molecule generation, reaction prediction. |
| Physics | Simulate complex systems, generate hypotheses. |
| Mathematics | Generate conjectures and proofs. |
| Neuroscience | Model brain activity, simulate neural networks. |
| Materials Science | Discover materials with targeted properties. |
Benefits:
- Accelerates hypothesis generation.
- Reduces manual experimentation time.
- Explores previously inaccessible solution spaces.
✅ 99. Potential Risks of Advanced Generative Models
| RISK | DESCRIPTION |
|---|---|
| Misuse by Bad Actors | Fake news, deepfake videos, phishing emails. |
| Automated Malware | Generate exploits or malicious code. |
| Social Manipulation | Influence elections, spread propaganda. |
| Loss of Trust | Erosion of confidence in digital media. |
| Unintended Consequences | Harmful or biased outputs produced unintentionally. |
| Concentration of Power | Few organizations controlling powerful AI systems. |
Solutions:
- Responsible release policies.
- Model watermarking and tracking.
- Public education and awareness campaigns.
✅ 100. Generative AI for Global Challenges
| CHALLENGE | AI CONTRIBUTION |
|---|---|
| Climate Change | Optimize energy use, simulate climate models. |
| Healthcare | Accelerate drug development, personalize treatment. |
| Education | Provide personalized learning for underserved regions. |
| Food Security | Improve crop yields via simulation and planning. |
| Disaster Response | Generate maps, simulate evacuation plans. |
| Poverty Alleviation | Enable microfinance, automate legal/health services. |
Example Use Case:
- Designing affordable vaccines for low-income countries using AI-driven molecular simulations.



