
Supervised Learning
What is Supervised Learning?
Supervised learning is a core machine learning paradigm where models are trained using labeled data—data that includes both input features (X) and corresponding output labels (y).
The goal of supervised learning is to learn a mapping function that can accurately predict outputs for new, unseen inputs by identifying patterns in the training data.
The term “supervised” comes from the fact that the model is trained with known correct answers. During training, the algorithm compares its predictions with the actual labels and adjusts its parameters to minimize prediction errors.
Types of Supervised Learning
Supervised learning problems are broadly categorized into classification and regression.
1. Classification
Classification models predict categorical or discrete outcomes.
- Examples:
- Email spam detection
- Image recognition
- Sentiment analysis
- Output:
- Class labels such as
"spam"/"not spam"or"cat"/"dog"/"bird"
- Class labels such as
2. Regression
Regression models predict continuous numerical values.
- Examples:
- House price prediction
- Stock price forecasting
- Temperature prediction
- Output:
- Numeric values such as
$350,000or72.5°F
- Numeric values such as
Key Characteristics of Supervised Learning
- Requires labeled data
Each training example must include both input features and the correct output. - Goal-oriented learning
The model explicitly learns a function that maps inputs to outputs. - Guided by ground truth
Known labels act as feedback for improving predictions. - Generalization capability
The model aims to perform well on unseen data, not just training samples. - Error-driven optimization
Learning is driven by minimizing a loss or error function.
Common Supervised Learning Algorithms
Classification Algorithms
- Logistic Regression
- Decision Trees
- Random Forest
- Support Vector Machines (SVM)
- Naive Bayes
- K-Nearest Neighbors (KNN)
- Neural Networks
Regression Algorithms
- Linear Regression
- Ridge and Lasso Regression
- Decision Tree Regression
- Gradient Boosting
- Neural Networks
Code Examples
Example 1: Classification Using the Breast Cancer Dataset
In this example, we use a Random Forest Classifier to predict whether a tumor is malignant or benign based on medical features.
Steps:
- Load the dataset
- Split data into training and testing sets
- Train a Random Forest model
- Evaluate performance using accuracy, classification report, and confusion matrix
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix
import seaborn as sns
import matplotlib.pyplot as plt
# Load dataset
cancer = load_breast_cancer()
X, y = cancer.data, cancer.target
# Split data
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
# Train model
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Make predictions
predictions = model.predict(X_test)
# Evaluate model
print("Classification Report:")
print(classification_report(y_test, predictions))
print(f"Accuracy: {model.score(X_test, y_test):.2f}")
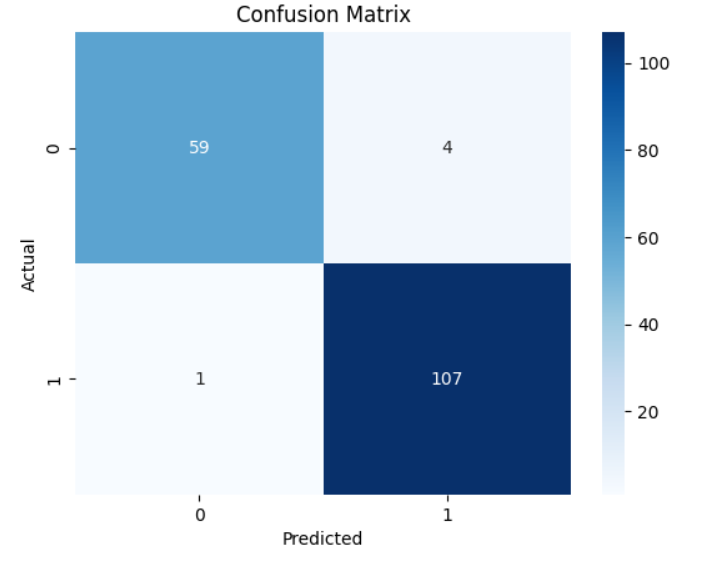
# Confusion Matrix
cm = confusion_matrix(y_test, predictions)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel("Predicted")
plt.ylabel("Actual")
plt.title("Confusion Matrix")
plt.show()
📌 Use Case: Medical diagnosis systems such as cancer detection.
Classification Report:
precision recall f1-score support
0 0.98 0.94 0.96 63
1 0.96 0.99 0.98 108
accuracy 0.97 171
macro avg 0.97 0.96 0.97 171
weighted avg 0.97 0.97 0.97 171
Accuracy: 0.97
Example 2: Regression Using the Diabetes Dataset
This example demonstrates regression using Ridge Regression to predict disease progression based on medical features.
Steps:
- Load the diabetes dataset
- Split data into training and testing sets
- Train a Ridge Regression model
- Evaluate using Mean Squared Error (MSE) and R² score
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
from sklearn.linear_model import Ridge
from sklearn.metrics import mean_squared_error, r2_score
import matplotlib.pyplot as plt
# Load dataset
diabetes = load_diabetes()
X, y = diabetes.data, diabetes.target
# Split data
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
# Train model
model = Ridge(alpha=1.0)
model.fit(X_train, y_train)
# Make predictions
predictions = model.predict(X_test)
# Evaluate model
mse = mean_squared_error(y_test, predictions)
r2 = r2_score(y_test, predictions)
print(f"Mean Squared Error: {mse:.2f}")
print(f"R-squared Score: {r2:.2f}")
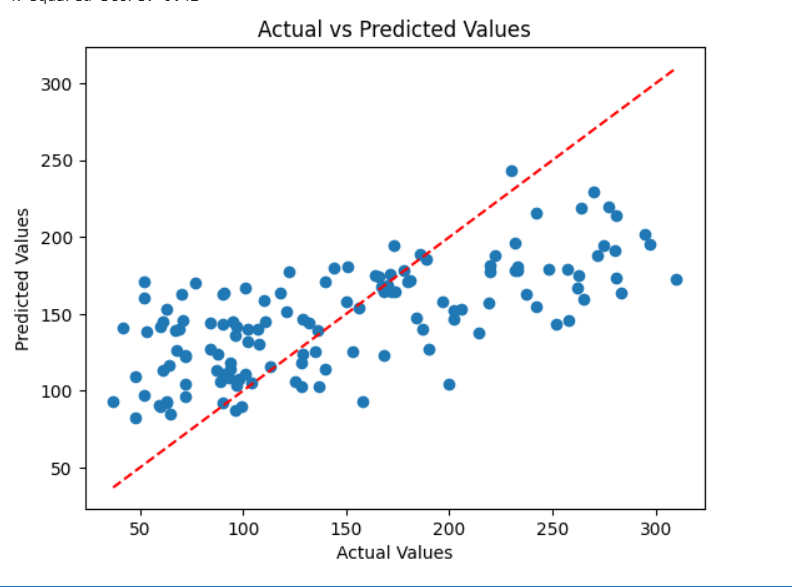
# Visualize Actual vs Predicted
plt.scatter(y_test, predictions)
plt.plot(
[min(y_test), max(y_test)],
[min(y_test), max(y_test)],
'r--'
)
plt.xlabel("Actual Values")
plt.ylabel("Predicted Values")
plt.title("Actual vs Predicted Values")
plt.show()
📌 Use Case: Predicting disease progression or continuous medical outcomes.
Mean Squared Error: 3112.97 R-squared Score: 0.42
Example 3: Support Vector Machine (SVM) for Classification
In this example, we use a Support Vector Machine (SVM) to classify handwritten digits from the Digits dataset. SVMs are powerful classifiers that work well for high-dimensional data.
Steps:
- Load the digits dataset
- Split data into training and testing sets
- Train an SVM with an RBF kernel
- Evaluate accuracy and visualize predictions
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
# Load dataset
digits = load_digits()
X, y = digits.data, digits.target
# Split data
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Train model
model = SVC(kernel='rbf', gamma='scale', C=1.0)
model.fit(X_train, y_train)
# Make predictions
predictions = model.predict(X_test)
# Evaluate model
accuracy = accuracy_score(y_test, predictions)
print(f"Accuracy: {accuracy:.2f}")
# Visualize predictions
fig, axes = plt.subplots(2, 5, figsize=(12, 6))
for i, ax in enumerate(axes.flat):
ax.imshow(X_test[i].reshape(8, 8), cmap='gray')
ax.set_title(f"Pred: {predictions[i]}\nTrue: {y_test[i]}")
ax.axis('off')
plt.tight_layout()
plt.show()
📌 Use Case: Handwritten digit recognition (e.g., OCR systems)

Example 4: Decision Tree for Classification
This example demonstrates how a Decision Tree Classifier can be used to classify wine samples based on chemical properties. Decision trees are intuitive and easy to interpret.
Steps:
- Load the wine dataset
- Train a decision tree with limited depth to avoid overfitting
- Evaluate accuracy
- Visualize the learned decision rules
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
# Load dataset
wine = load_wine()
X, y = wine.data, wine.target
# Split data
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
# Train model
model = DecisionTreeClassifier(max_depth=3, random_state=42)
model.fit(X_train, y_train)
# Make predictions
predictions = model.predict(X_test)
# Evaluate model
accuracy = accuracy_score(y_test, predictions)
print(f"Accuracy: {accuracy:.2f}")
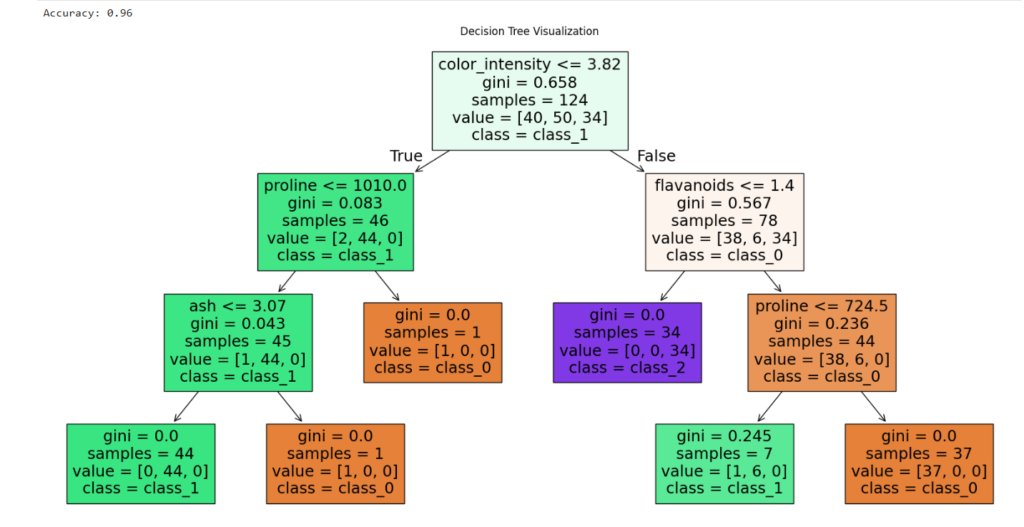
# Visualize the decision tree
plt.figure(figsize=(20, 10))
plot_tree(
model,
feature_names=wine.feature_names,
class_names=wine.target_names,
filled=True
)
plt.title("Decision Tree Visualization")
plt.show()
📌 Use Case: Explainable ML models in finance and healthcare.
Example 5: Neural Network for Regression
This example uses a Multilayer Perceptron (MLP) to predict house prices using the California Housing dataset. Neural networks are powerful for modeling complex, non-linear relationships.
Steps:
- Load and split the dataset
- Standardize features
- Train a neural network regressor
- Evaluate performance using RMSE
- Visualize actual vs predicted values
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.neural_network import MLPRegressor
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error
import numpy as np
import matplotlib.pyplot as plt
# Load dataset
housing = fetch_california_housing()
X, y = housing.data, housing.target
# Split data
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Scale features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Train model
model = MLPRegressor(
hidden_layer_sizes=(100, 50),
max_iter=1000,
random_state=42
)
model.fit(X_train_scaled, y_train)
# Make predictions
predictions = model.predict(X_test_scaled)
# Evaluate model
rmse = np.sqrt(mean_squared_error(y_test, predictions))
print(f"Root Mean Squared Error: {rmse:.2f}")
print(f"Mean house price: ${np.mean(y_test) * 100000:.2f}")
# Visualize results
plt.figure(figsize=(10, 6))
plt.scatter(y_test, predictions, alpha=0.5)
plt.plot(
[min(y_test), max(y_test)],
[min(y_test), max(y_test)],
'r--'
)
plt.xlabel("Actual House Price (×$100,000)")
plt.ylabel("Predicted House Price (×$100,000)")
plt.title("California Housing Price Prediction")
plt.show()
📌 Use Case: Real estate price prediction and economic modeling.
this is not working load data set
✅ Neural Network Regression Using housing.csv (Manual Dataset Loading)
🔹 Expected CSV Columns (standard California Housing)
Your housing.csv should contain:
longitudelatitudehousing_median_agetotal_roomstotal_bedroomspopulationhouseholdsmedian_incomemedian_house_value← TARGET
✅ Final Working Code (CSV Version)
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.neural_network import MLPRegressor
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error
import numpy as np
import matplotlib.pyplot as plt
# Load dataset
df = pd.read_csv("housing.csv")
# Handle missing values
df["total_bedrooms"].fillna(df["total_bedrooms"].median(), inplace=True)
# One-Hot Encode categorical column
df = pd.get_dummies(df, columns=["ocean_proximity"], drop_first=True)
# Separate features and target
X = df.drop("median_house_value", axis=1)
y = df["median_house_value"]
# Train-test split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Feature scaling
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Train Neural Network
model = MLPRegressor(
hidden_layer_sizes=(100, 50),
max_iter=1000,
random_state=42
)
model.fit(X_train_scaled, y_train)
# Predictions
predictions = model.predict(X_test_scaled)
# Evaluation
rmse = np.sqrt(mean_squared_error(y_test, predictions))
print(f"Root Mean Squared Error: {rmse:.2f}")
print(f"Average house price: ${y_test.mean():,.2f}")
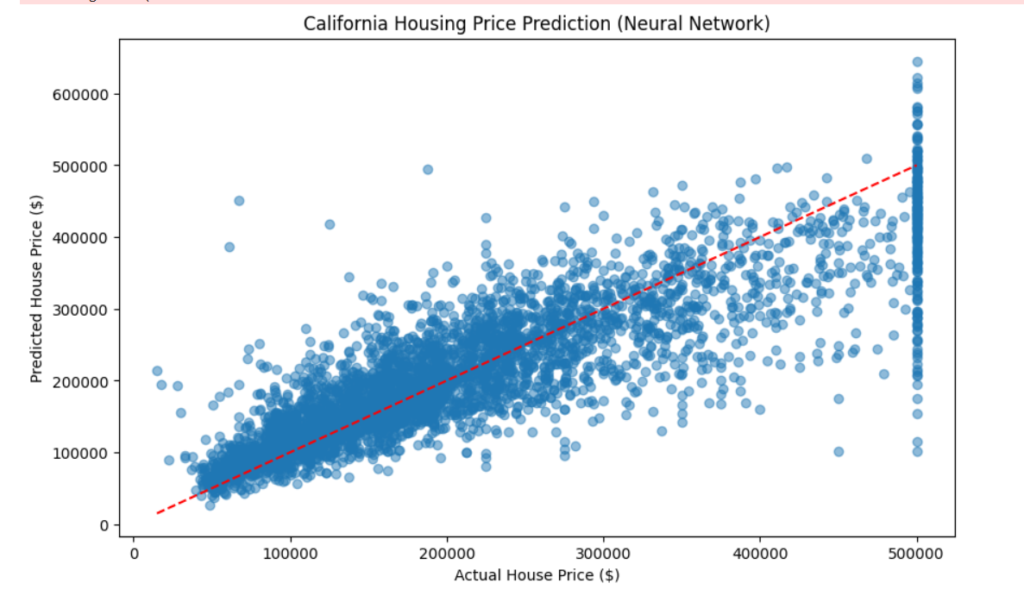
# Visualization
plt.figure(figsize=(10, 6))
plt.scatter(y_test, predictions, alpha=0.5)
plt.plot(
[y_test.min(), y_test.max()],
[y_test.min(), y_test.max()],
'r--'
)
plt.xlabel("Actual House Price ($)")
plt.ylabel("Predicted House Price ($)")
plt.title("California Housing Price Prediction (Neural Network)")
plt.show()
)
plt.xlabel("Actual House Price ($)")
plt.ylabel("Predicted House Price ($)")
plt.title("California Housing Price Prediction (Neural Network)")
plt.show()
Root Mean Squared Error: 59833.88 Average house price: $205,500.31
5 Real-World Applications of Supervised Learning
1. Email Spam Detection
- Input: Email content, sender address, subject line, metadata
- Output: Spam / Not Spam
- Algorithms: Naive Bayes, Support Vector Machines (SVM), Logistic Regression
- Use Case: Gmail and Outlook spam filters
2. Medical Diagnosis
- Input: Patient symptoms, lab test results, medical history
- Output: Disease classification (e.g., diabetic / non-diabetic)
- Algorithms: Decision Trees, SVM, Neural Networks
- Use Case: Cancer detection, diabetes prediction
3. Credit Scoring
- Input: Income, credit history, employment status, existing debt
- Output: Credit score or loan approval / rejection
- Algorithms: Logistic Regression, Random Forest
- Use Case: Bank loan and credit card approvals
4. House Price Prediction
- Input: Location, square footage, number of rooms, house age
- Output: Estimated house price
- Algorithms: Linear Regression, Gradient Boosting
- Use Case: Real estate valuation platforms like Zillow
5. Image Recognition
- Input: Image pixel values
- Output: Object categories (e.g., cat, dog, car)
- Algorithms: Convolutional Neural Networks (CNNs)
- Use Case: Facebook photo tagging, autonomous vehicles
Best Practices in Supervised Learning
- Data Preprocessing:
Handle missing values, scale numerical features, and encode categorical variables. - Model Selection:
Choose algorithms based on the problem type, dataset size, and complexity. - Hyperparameter Tuning:
Use techniques likeGridSearchCVorRandomizedSearchCVto optimize model performance. - Cross-Validation:
Apply k-fold cross-validation to ensure reliable performance estimates. - Feature Engineering:
Create meaningful features from raw data to improve model accuracy. - Regularization:
Use L1 (Lasso) or L2 (Ridge) regularization to prevent overfitting. - Ensemble Methods:
Combine multiple models to achieve better generalization and robustness.
Evaluation Metrics
Classification Metrics

Regression Metrics
- Mean Absolute Error (MAE):
Average absolute prediction error - Mean Squared Error (MSE):
Average squared prediction error - R-squared (R²):
Proportion of variance explained by the model - Root Mean Squared Error (RMSE):
Square root of MSE



